



What is a Convolutional Neural Network?
3 things you need to know
A convolutional neural network (CNN or ConvNet), is a network architecture for deep learning which learns directly from data, eliminating the need for manual feature extraction.
CNNs are particularly useful for finding patterns in images to recognize objects, faces, and scenes. They can also be quite effective for classifying non-image data such as audio, time series, and signal data.
Applications that call for object recognition and computer vision — such as self-driving vehicles and face-recognition applications — rely heavily on CNNs.
Why CNNs Matter |
How They Work |
CNNs with MATLAB |
What Makes CNNs So Useful?
Using CNNs for deep learning is popular due to three important factors:
- CNNs eliminate the need for manual feature extraction—the features are learned directly by the CNN.
- CNNs produce highly accurate recognition results.
- CNNs can be retrained for new recognition tasks, enabling you to build on pre-existing networks.
 |
Deep learning workflow. Images are passed to the CNN, which automatically learns features and classifies objects.
CNNs provide an optimal architecture for uncovering and learning key features in image and time-series data. CNNs are a key technology in applications such as:
- Medical Imaging: CNNs can examine thousands of pathology reports to visually detect the presence or absence of cancer cells in images.
- Audio Processing: Keyword detection can be used in any device with a microphone to detect when a certain word or phrase is spoken – (‘Hey Siri!’). CNNs can accurately learn and detect the keyword while ignoring all other phrases regardless of the environment.
- Stop Sign Detection: Automated driving relies on CNNs to accurately detect the presence of a sign or other object and make decisions based on the output.
- Synthetic Data Generation: Using Generative Adversarial Networks (GANs), new images can be produced for use in deep learning applications including face recognition and automated driving.
How CNNs Work
A convolutional neural network can have tens or hundreds of layers that each learn to detect different features of an image. Filters are applied to each training image at different resolutions, and the output of each convolved image is used as the input to the next layer. The filters can start as very simple features, such as brightness and edges, and increase in complexity to features that uniquely define the object.
Feature Learning, Layers, and Classification
Like other neural networks, a CNN is composed of an input layer, an output layer, and many hidden layers in between.

These layers perform operations that alter the data with the intent of learning features specific to the data. Three of the most common layers are: convolution, activation or ReLU, and pooling.
- Convolution puts the input images through a set of convolutional filters, each of which activates certain features from the images.
- Rectified linear unit (ReLU) allows for faster and more effective training by mapping negative values to zero and maintaining positive values. This is sometimes referred to as activation, because only the activated features are carried forward into the next layer.
- Pooling simplifies the output by performing nonlinear downsampling, reducing the number of parameters that the network needs to learn.
These operations are repeated over tens or hundreds of layers, with each layer learning to identify different features.
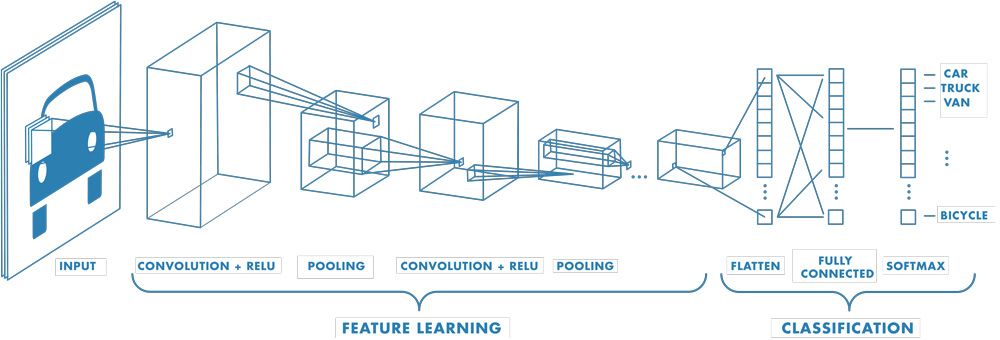
Example of a network with many convolutional layers. Filters are applied to each training image at different resolutions, and the output of each convolved image is used as the input to the next layer.
Shared Weights and Biases
Like a traditional neural network, a CNN has neurons with weights and biases. The model learns these values during the training process, and it continuously updates them with each new training example. However, in the case of CNNs, the weights and bias values are the same for all hidden neurons in a given layer.
This means that all hidden neurons are detecting the same feature, such as an edge or a blob, in different regions of the image. This makes the network tolerant to translation of objects in an image. For example, a network trained to recognize cars will be able to do so wherever the car is in the image.
Classification Layers
After learning features in many layers, the architecture of a CNN shifts to classification.
The next-to-last layer is a fully connected layer that outputs a vector of K dimensions where K is the number of classes that the network will be able to predict. This vector contains the probabilities for each class of any image being classified.
The final layer of the CNN architecture uses a classification layer such as softmax to provide the classification output.
Designing and Training CNNs Using MATLAB
Using MATLAB® with Deep Learning Toolbox™ enables you to design, train, and deploy CNNs.
MATLAB provides a large set of pretrained models from the deep learning community that can be used to learn and identify features from a new data set. This method, called transfer learning, is a convenient way to apply deep learning without starting from scratch. Models like GoogLeNet, AlexNet and Inception provide a starting point to explore deep learning, taking advantage of proven architectures built by experts.
Designing and Training Networks
Using Deep Network Designer, you can import pretrained models or build new models from scratch.

Deep Network Designer app, for interactively building, visualizing, and editing deep learning networks.
You can also train networks directly in the app, and monitor training with plots of accuracy, loss, and validation metrics.
Using Pretrained Models for Transfer Learning
Fine-tuning a pretrained network with transfer learning is typically much faster and easier than training from scratch. It requires the least amount of data and computational resources. Transfer learning uses knowledge from one type of problem to solve similar problems. You start with a pretrained network and use it to learn a new task. One advantage of transfer learning is that the pretrained network has already learned a rich set of features. These features can be applied to a wide range of other similar tasks. For example, you can take a network trained on millions of images and retrain it for new object classification using only hundreds of images.
Hardware Acceleration with GPUs
A convolutional neural network is trained on hundreds, thousands, or even millions of images. When working with large amounts of data and complex network architectures, GPUs can significantly speed the processing time to train a model.

NVIDIA® GPU, which accelerates computationally intensive tasks such as deep learning.